This is the first in a series of two articles detailing a major optimization I implemented in one of my projects:
- How I reduced the costs of my project by 75% (you're here)
- How I improved the performance of my project by 3x (soon)
Introduction
There is several ways to increase businesses profit. In fact, ChatGPT can list you many of them:

But one of the most efficient ways to increase profit is actually to reduce costs. And this is what we're going to talk about!
A glimpse of our architecture
First of all, let me give you some context. (Note: I will simplify things).
Our project is basically a bot that, after performing a series of validations based on some rules, sends messages on Telegram.
The trick is that each user can create and modify their own bots, configuring their own set of rules. From now on, let's refer to these bots as tasks.
Our backend, built with Node.js, is a cron job that runs every X minutes, fetching all tasks from Firestore and executing necessary processes for each one of them.

For a long time, this architecture was good enough for the project: it's simple, fast and easy to work with. Until it's not…
When things start to get complicated
As we implemented the simplest architecture possible to launch our product, we knew that, if things went well, we would eventually need to improve it.
The plan here is to focus on the technical challenges of the product. I'm not going to dig into marketing, pricing, planning, prioritizing, sales and all of the crucial pieces that need to fit together in order to have a successful product. So let's just say that we ended up having users. Thousands of users.
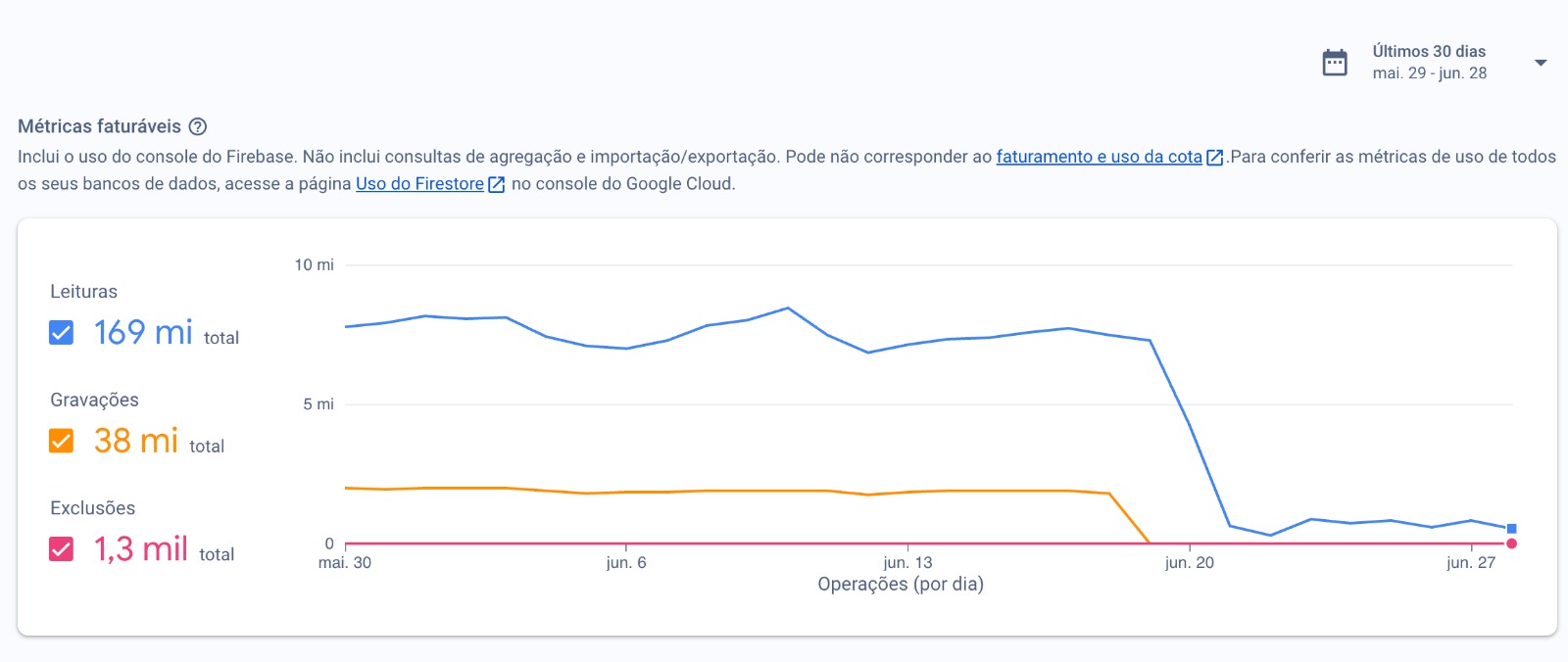
Long story short, we found ourselves managing ~150,000 tasks, what was leading us to ~8.2 million Firestore reads per day, or ~245 million reads per month. Please, don't get me wrong: we love our users and we're super happy to solve their problems. But Firestore costs can get crazy!
Finding a solution
As you may know, Firestore charges per read. So we figured we should migrate to a database with a different billing system.
The first option we considered was to do a full migration. Since we already have most of our infrastructure on Digital Ocean, it was easy to host a database server and just start using it. By doing some research, I found Postgres to be a really interesting and simple option.
Based on my research, I found out that Postgres can manage some kind of JSON data type. Reading this really hyped me up. I thought: “This is PERFECT! I can quickly migrate all our data and I won't have to think about modeling the whole thing within the ‘Relational’ structure. So easy and fast!”.
Then, I created a Postgres server on Digital Ocean and wrote all of the necessary scripts to send all tasks data from Firestore to Postgres so we could start running tests. I was very optimistic about this solution, since it sounded very likely to almost eliminate our costs problem.
As soon as I got to test it with real data, the solution showed itself worthless. It was too slow. Since we use Firestore, which is a NoSQL database, we have a lot of fields that behave basically as a JSON* record. The problem is that these JSON's can get pretty big depending on what you're doing with it, and after going deep on tests and experiments, I saw that Postgres was not really enjoying dealing with giant JSONs. I concluded that in order to be able to use Postgres correctly, I would have to actually remodel all my data to get along with the Relational structure. This was not an option for me, I had to go fast.
I want to clarify I'm NOT a Postgres - not even a “database” or “backend” - expert. I'm just a Frontend Engineer trying to build things. So, to my fellow Backend masters and Postgres lovers: I'm sorry if I offend you, I mean no harm.
Giving up is not an option
My second try was actually my first option, but I didn't tried it first because I thought it would be too hard: ✨ Redis ✨
When we face this kind of problem, implementing a cache layer with Redis seems to always be an obvious choice. Especially in our case: we already had a Redis server we use to do other things running on Digital Ocean, so it was easy to just connect to it and start experimenting with it.
This sounds very cool, but it also brings serious challenges:
- How can we apply a Redis cache layer in our architecture?
- How to manage cache invalidation? Consider our users can create new tasks, edit existing ones, delete it, deactivate it, activate it, and so on…
After testing some possibilities and thinking a lot about what could be a suitable solution considering time, costs and the tools we have available, I finally came up with an idea I liked.
For those who don't know, Firebase provides a tool called Cloud Functions. To keep it short, it is a serverless framework that lets you automatically run backend code in response to events. For example: you can write some code and they will run it when a document gets updated.
It seemed clear I could leverage Cloud Functions, and this is what I did:
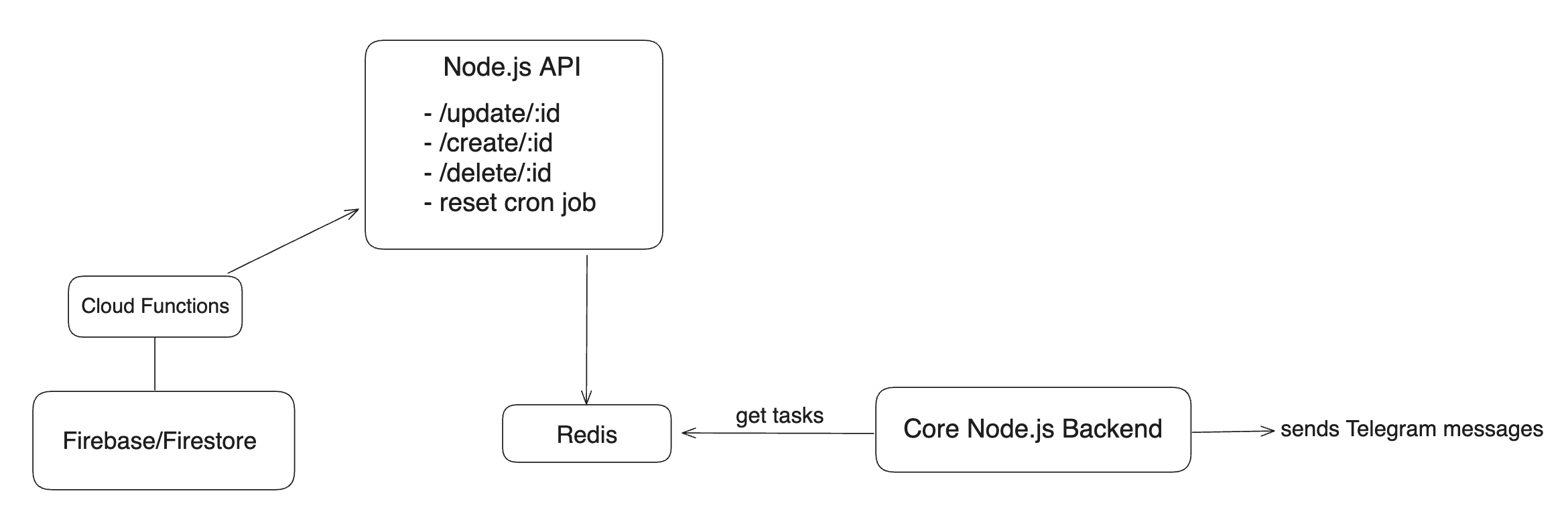
I wrote a script to get all tasks data and store it on Redis. Then, I created a Node API with endpoints to handle cache updates as necessary: there's one endpoint to add a task to the cache; one endpoint to update a task that's already cached; and finally an endpoint to delete a task from the cache.
On Cloud Functions, I wrote code to run onCreate , onUpdate and onDelete. These functions only duty is to basically call the correct endpoints on my Node API and to send data to it.
As I'm not confident on my backend skills, I also wrote a cron job to update the Redis cache based on what's stored on Firestore. It's basically a reset of the cache that runs once a day. I do it to guarantee it's all correctly synchronized, I consider it an extra safety layer.
Here's my - failed - try to represent this idea in a simple drawing:
Great results
It all took work, but it was very worth it. I was able to achieve excellent results, here's a screenshot from a few days after deployment:
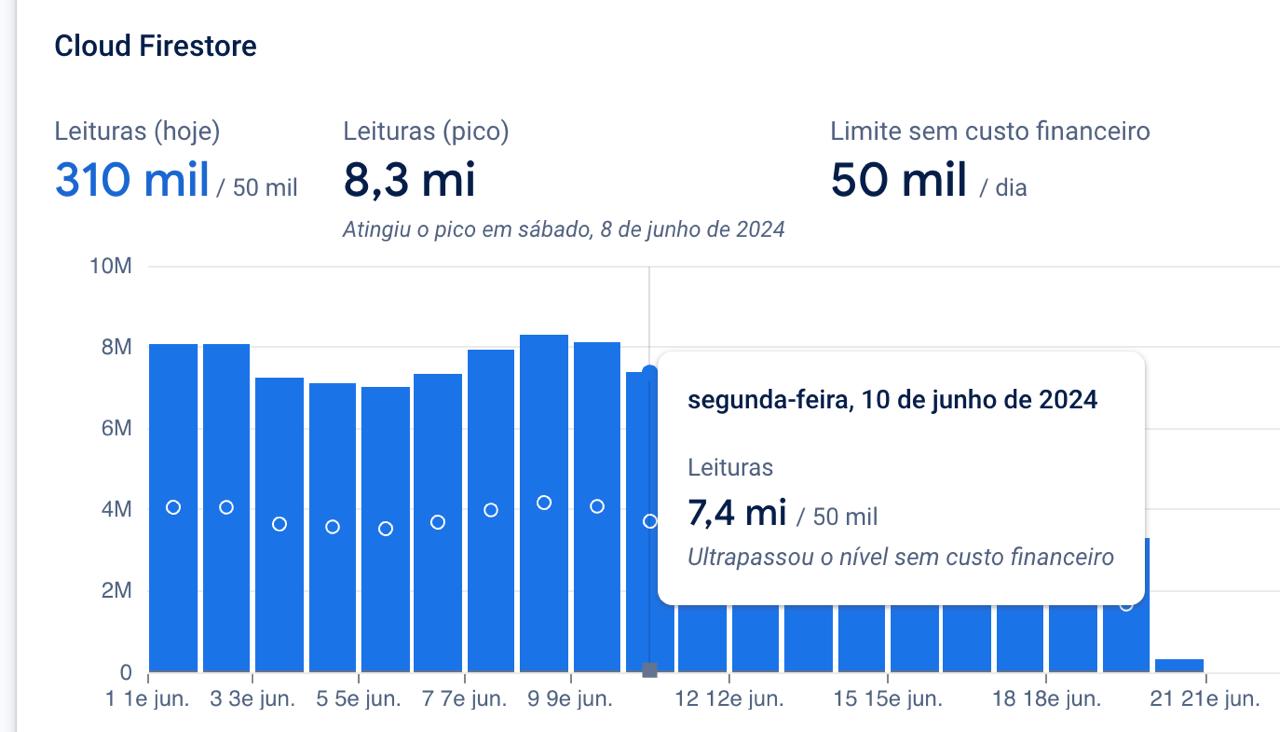
As you can see, there's a huge drop on reads after I deployed this new architecture. We went from 8M+ to ~500k reads per day.
We still have some weird read spikes that I have no idea where they comes from or why it's happening, but I'll certainly investigate it soon. Here's a screenshot of our average reads per day:
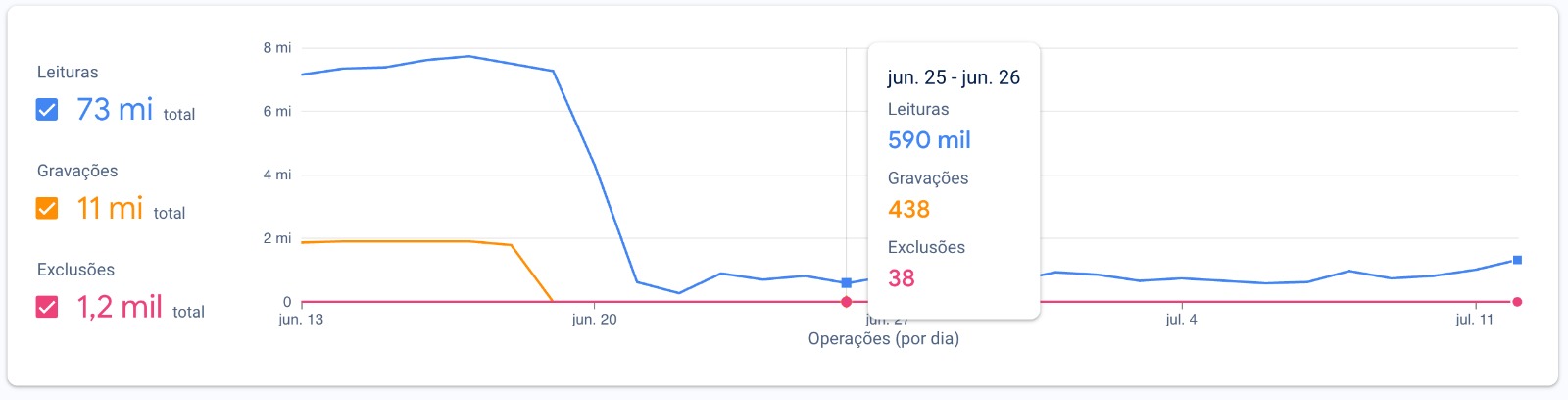
And here's another screenshot I took some time after deployment:
Conclusion
Based on this experience, I would recommend avoiding databases that charge per read. Firestore was fantastic for a quick start, but as our user base grew, so did the costs, exponentially.
If you have any questions, don't hesitate to reach out to me on Twitter or LinkedIn. Thank you!